Back to Blog
General
=nil; Trustless Data Management
What total trustless data accessibility leads to
31 May 2022
What is this about?
Data management of any type (whatever OLAP or OLTP-alike load) requires having some access to the data. Critical data management though requires having data on hand. A full replica in a trusted environment under full control. But what if no such a possibility exists (because of, for example, costs reasons)? A usual solution is - to trust the data provider. Just like they do with AWS or Infura. Guess what this leads to? Here you go: https://www.coindesk.com/policy/2022/03/03/metamask-infura-block-certain-areas-amid-crypto-sanctions-fury/.
Now, what if such a trusted data source requires to be emplaced and used within some other database (aka for a so-called “bridge”)? Well, here what unfortunately happens: https://www.coindesk.com/business/2022/08/02/nomad-hacked-45m-stolen-so-far-report/, https://www.theverge.com/2022/2/3/22916111/wormhole-hack-github-error-325-million-theft-ethereum-solana.
That is why this post =nil;’s trustless data management solution which is supposed to solve those issues with state and query proofs based upon =nil; `DROP DATABASE * by bringing three major use cases together:
- Trustless (non-optimisitic) data retrieval and insertion. Retrieve and insert the data from and to different databases (fault-tolerant full-replica included aka Bitcoin or Ethereum or whatever) through simple query language (SQL or JS-based one) without any need to trust data providers becuase of SNARK data correctness proofs.
- Trustless bridging. Use the data retrievied from the protocol and a SNARK correctness proof for putting the data from different protocols databases to each other.
- Pluggable trustless scaling. Use the data retrieved from the protocol and a SNARK correctness proof to increase the throughput of a particular protocol by deploying several independent application-specific clusters.
=nil; `DROP DATABASE *?
=nil; `DROP DATABASE * is a database management system developed by =nil; Foundation with a purpose to handle publicly-replicable fault-tolerant full-replica databases (e.g. Bitcoin or Ethereum) with a single piece of software - just like it is being done with a proper DBMS (e.g. MySQL or PostgreSQL). This allows to:
- Introduce a unified read AND write query language for such databases
- Reduce deployment and maintenance costs by managing multiple databases within the single piece of software-based cluster or a standalone deployment.
- Increase deployments durability by using good old DBMS-specific techniques.
More detailed information about =nil; `DROP DATABASE * can be found in a relevant blog post: https://blog.nil.foundation/2021/12/01/database-management-system.html.
But what does it have to do with trustless data management protocol?
=nil; `DROP DATABASE * eliminates data accessibility and maintenance cost problems as if they never existed. This is done by managing several publicly-replicable fault-tolerant full-replica databases with the same piece of software and by providing a read/write query language, same to all the databases, which replication protocols are supported. Typical DBMS features. Another typical modern DBMS feature is clusterization. Same thing =nil; `DROP DATABASE * provides as well.
Having any public databases’ (or protocol’s if you really like that name) data manageable with the same language, naturally induces the desire to start a publicly-replicatable cluster on top of such a solution and see what can be achieved with this. This leads to the necessity to introduce some native replication protocol, besides third-party ones, capable of providing such data accessibility.
Just as with third-party replication protocols, native replication protocol should be compliant to the replication protocol adapter interface. And it also has to be capable of providing users with a proper throughput for the data retrieval from many different databases to be possible.
Okay. What it is going to be?
Traditional DBMS-provided clusterization is a network communication-based, by-design fragile in favor of replication/partitioning performance and is supposed to work within trusted environments (e.g. Raft or etcd-alike ones). If any fault-tolerance is achieved within such consensus algorithms family (e.g. Byzantine Paxos), it is, again, very sensitive to network communication environment and is supposed to handle minor participants misbehaviour at its best.
Less fragile clusterization is usually achieved by on-data consensus, leaving networking to deal with data transfers only. Bitcoin, Ethereum and others use this kind of clusterization to maintain database clusters of extremely low consistency, but of a proper availability.
So, what do we end up with regarding clusterization options for =nil; `DROP DATABASE *-based clusters (for the sake of proper architecture generalization)?
- Network-based clusterization:
- Partitioning (implementations differ, we gotta figure out our own one). Used to split cluster’s nodes state to several servers. So that would work only in case of a trusted-environment setup.
- Replication (Raft, Paxos, etcd, etc.). Again, low-scale clusters within trusted environment setup.
- Data-based clusterization:
- Replication (literally sacrificing consistency in favor of accessbility). Mesh-based networking, noisy as hell (in terms of networking), but publicly accessible. This option also seems to be the best way to exploit total data accessibility.
But! The actual publicly-replicatable database cluster replication protocol design will depend on a purpose of an application.
Alright. So let’s pick a purpose then. Something useful please.
Sure.
The most obvious thing is to exploit something no one else has - total data accessibility. To provide every protocol with every other protocol’s data, for example. Or to provide end-user applications with an entrypoint to any database.
There is a couple of options on how to set this up:
-
Set up a managed DBMS hosting, which would contain all the clusters’ data (aka Infura with SQL).
Guess, what is the problem with that? It is hard to scale (especially nowadays) given extensive infrastructure which should be managed by the only organization - some =nil; Foundation-related one. We also already have Amazon, Google Cloud, Azure, etc, which are also not reliable data sources — we should not have to trust data providers to behave honestly by providing the correct data.
Doesn’t seem like an option to me.
-
Set up a publicly-replicable database cluster so that any and every willing party could permissionlessly join at any time—this would also simultaneously strengthen the data-providing infrastructure.
I like this option because it scales better and still retains the performance of a data provider-like managed DBMS solution. All that is required are for several participants to enable the necessary protocol replication adapters (e.g. Bitcoin, Ethereum and Polkadot in a single node at the same time).
But then a data-providing publicly-replicatable database cluster will require:
- Throughput limitation mechamism to avoid spamming the databases’ contents
- In case such a throughput limitation mechanism is introduced, this will require for the overall-database consistent index containing such a rate limitation status description to be handled by all the database cluster members in a fault-tolerant replication-enabled full replica-like manner.
If we go with option 2, the data-providing publicly-replicable database cluster will require mechanisms to deal with its trustless nature, namely throttling. Specifically, we will need a throughput limitation mechanism to avoid spamming the database’s contents. This would then require all the database cluster participants to maintain a full replica of a global throughput index.
If the throttling component is implemented together with replication protocol adapters, then any willing party can join the publicly-replicable database cluster. This would allow them to synchronize third-party data into the =nil; `DROP DATABASE * instance, which then let them provide users with READ and WRITE access to various databases (e.g. Bitcoin, Ethereum, Solana, etc.) through a unified query language (e.g., a SQL-based language or some imperative, for example, JS-based one).
But this results into a data-providing relayer. Any way to make it trustless?
Now we’re talking. You’re absolutely right, it is better not to trust relayers.
Why? Forcing data consumers to trust relayers is obviously suboptimal since their only protection against malicious relayers providing fake data are weak game-theoretic guarantees.
Thus, we need to remove a necessity to trust the data provider.
There are several ways to do that:
-
The most obvious way is to strenghten those game-theoretic assumptions with punishing retroactively those protocol members who attempted to provide a fake data with enabling users to submit a complaint about them. Something like what those “the Graph” or “Pocket Network” things do. But! This results into so-called “optimistic security” when a plain-old dumb massive data fraud is prevented (which is more of a hooliganism than a fraud), but nothing prevents an attacker to wait for a very particular transaction and give away fake data exactly in the moment a particular transaction comes in.
By the way. What does that even mean? “Optimistic security”. “Most probably it is secure”? “Most probably nothing will be stolen?”
Oh oh, wait a minute, I got a better one. Read this with a typical Karen’s voice.
“When your funds are stolen because of the “optimistic security” - please file a complaint. A protocol’s secretary (imagine such one exists) will consider it and send you a written notice about the descision made via US Post”. Thank you for using our “optimistic security” protocol services.
No, thank you.
-
A better approach would be to not rely on game-theoretic guarantees at all. Specifically, this would require that a user performing some query can be sure about the source of the data being returned without having to verify the retrieval process themselves (e.g., by repeating the computation themselves).
How do we do that? Let us use whatever we have in disposal. What we have in disposal is =nil; `DROP DATABASE *. And what a typical DBMS has in disposal is a query engine/planner.
So! Generating a SNARK proof for the query planner results into having the actual data returned by a query proved to be correctly extracted from the database’s (e.g. Solana or Ethereum) state stored within the =nil; `DROP DATABASE *.
Actually, let’s consider an example proof for the following table returned by a =nil; `DROP DATABASE * SQL query over Solana’s state.
account : STRINGvalue : INTEGER8zJd5X6VqbTQNJ27QJ3cW5aCJy5UqKAcrPUe6HfBi1C3 2048 3C1iBfH6eUPrcAKqU5yJCc5Wc3JQ72JNQTbqV6X5dJz8 1024 Now, let’s consider, which circuit would be most convenient for proving this trivial kind of data structure?
Most probably, it is going to be a range proof (formal definition example: https://hackmd.io/@dabo/B1U4kx8XI) for the
INTEGERand a plookup-enhanced bitvector proof for theSTRINGtype. And all the proof will have database’s data as a private input. Most probably.But! How to prove that a particular query result doesn’t only belongs to correctly unpacked particular database’s state in the DBMS, but also that the databases’s (e.g. Solana’s) state itself was unpacked from the correct commit log (e.g. belongs to the actual Solana’s so-called “block sequence”)?
Notice, however, that proving the above requires an additional input to the proof, namely a…
A state proof!
Yes! Exactly those ones we’ve developed with Solana and Mina fellows for those Solana to Ethereum and Mina to Ethereum bridges projects of ours.
And, for those clusters, which do not have their own state proof, Solana-alike approach is going to be used. Those clusters, which have a state proof of their own (e.g. Mina, Celo, others), they will enjoy query proofs almost out of the box.
Does it get together in a bigger picture now, huh?
Yes, but these are just bridges, and you were talking about something entirely different. How is this all relevant?
Pretty simple. State proof in combination with =nil; `DROP DATABASE * query proofs can lead to different kind of applications. It all depends on how does one apply ones.
Essentially, all along, our bridge projects were just experiments to test corner-cases of third-party cluster integrations into our protocol.
Let’s now consider a few applications that can be built using our protocol. We will showcase these use cases through an incredibly innovative tool—a tool that in our opinion represents the future of blogging — and something we have never used before: PICTURES.
Trustless Data Retrieval
The first use case that can be built on top of our protocol is what we outlined earlier: trustless data retrieval. How does our protocol facilitate this?
- A user (e.g., an application frontend) comes to our protocol looking for some data.
- They query into a =nil; `DROP DATABASE *-based database cluster.
- The protocol retrieves the data along with a proof. This proof guarantees that the data was retrieved from the database state correctly and that the data was unpacked correctly from the target database cluster’s commit log.
You might now wonder how we would prevent a DBMS node from giving out a fake proof. Easy. Since all the nodes of the cluster are =nil; `DROP DATABASE * nodes (which have access to all the external publicly-replicable databases data at once) the protocol would require that the proof be published and verified by the rest of the cluster members before the data is sent to the user.
This means that a query proof-generating node has to be incentivised to provide a proof along with the data to the user. This means the reward for a particular query has to be scored only when a valid query proof is published and verified by all the I/O protocol extension cluster participants.
And here we go. Trustless data access to various protocols data via the same =nil; `DROP DATABASE * query language.
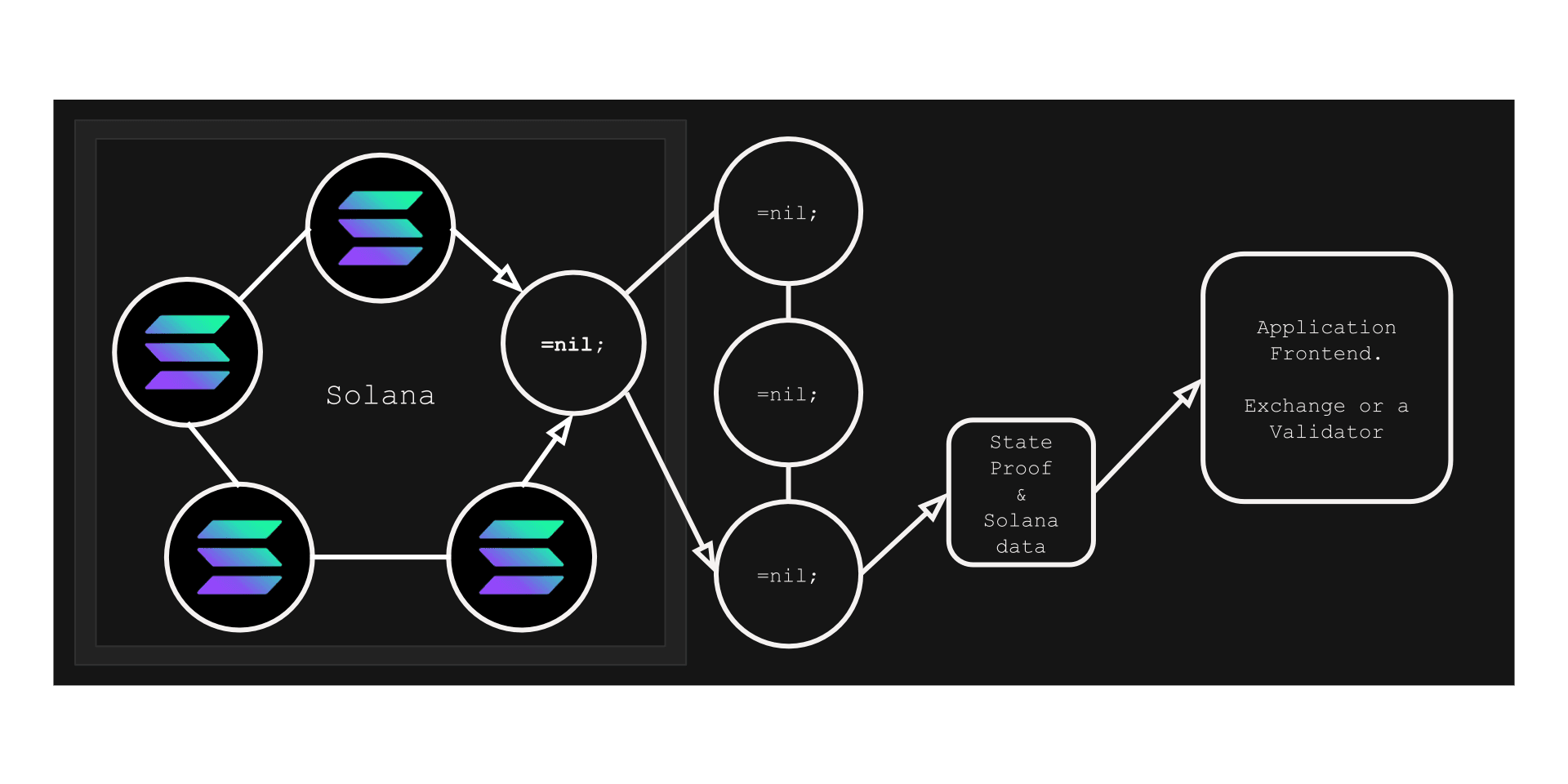
Trustless Bridging
Let us now consider a case when a client is not an application frontend, or an exchange, or a validator (any external data consumer), but a third-party protocol.
Let us say, we have Solana’s/Avalanche’s/any other monolithic L1’s cluster. And let us say, within such a cluster there is a =nil; `DROP DATABASE * node with Solana’s replication protocol adapter. It behaves like Solana’s node (a full featured one), it quacks like one, it swims like one. But it is not exactly one.
Such a special node provides Solana’s data in the way suitable for the =nil; `DROP DATABASE *-based cluster to be able to track it, it is possible to generate the state proof out of Solana’s data (of a particular moment in time) every time a user requests it with a query.
After the state/query proof was generated by the =nil; `DROP DATABASE *-based cluster, it is supposed to be submitted to the client protocol (e.g. Mina or Ethereum), where it is supposed to verified, allowing users to use the third-party’s cluster data.
Here we go. Trustless on-demand bridging for various protocols via the same =nil; `DROP DATABASE * query language.
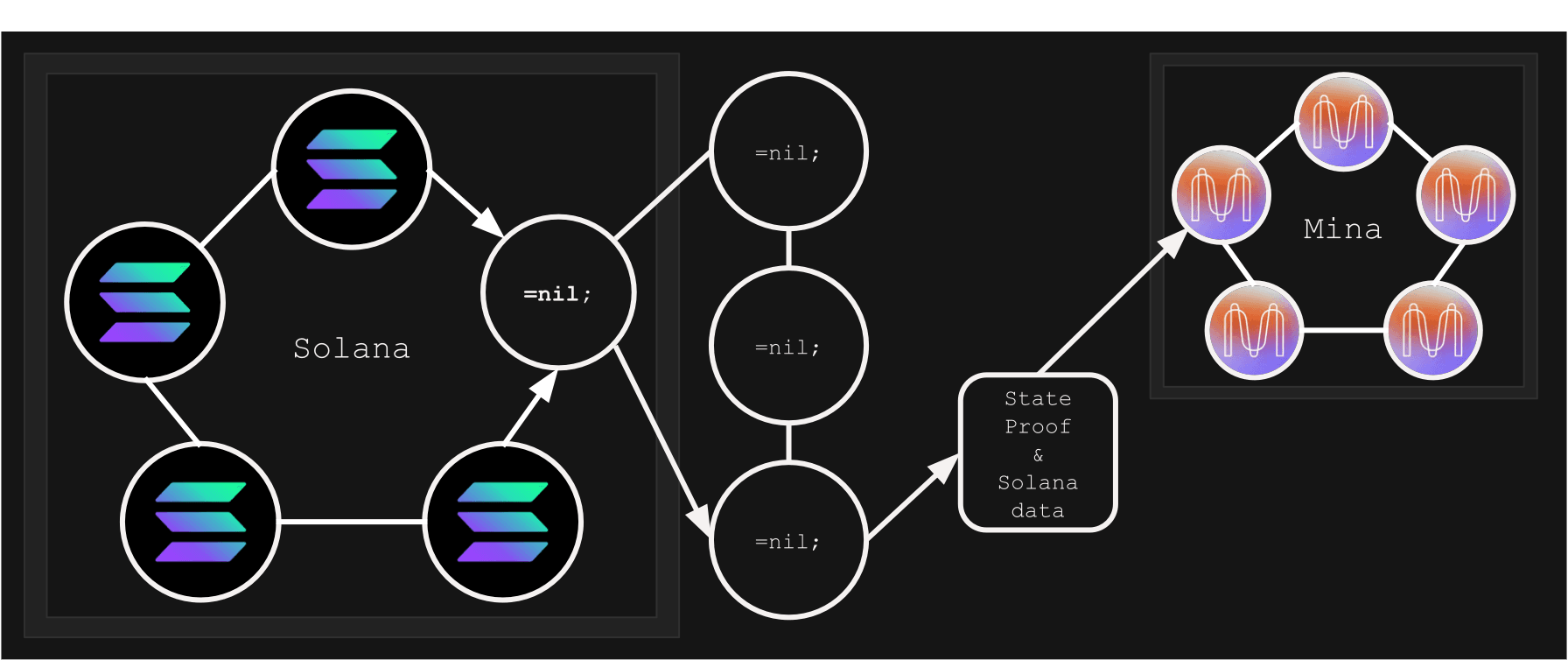
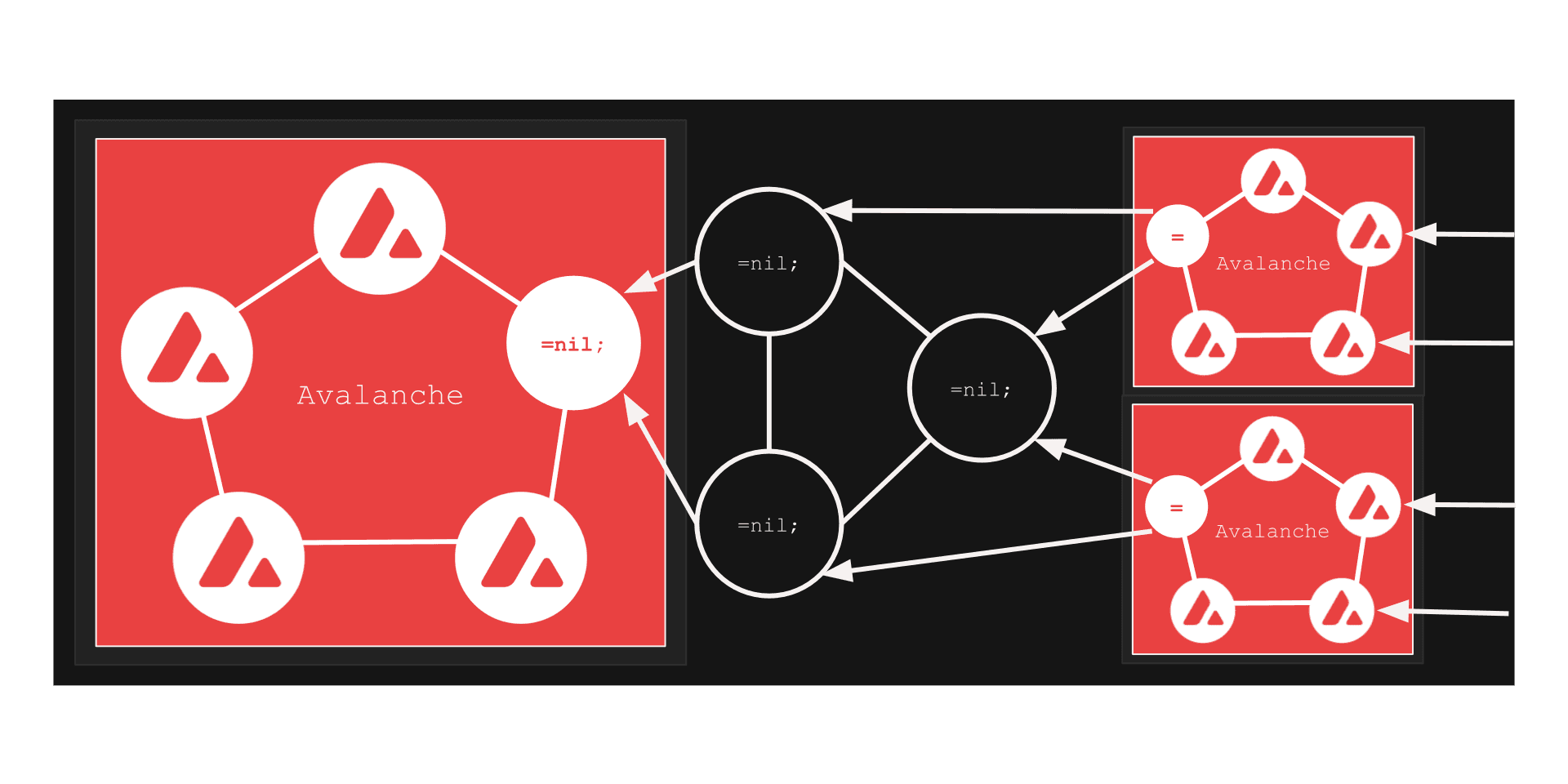
Pluggable Scaling
And now we move on to yet another example of a use case enabled by our protocol.
In the previous example, we considered the case where the clusters on both sides of our protocol were different (e.g., Ethereum and Solana, Solana and Mina, etc). But what happens when the clusters on both sides are the same type (e.g., Avalanche and Avalanche)?
Now let us say, within the that L1 cluster (e.g. Avalanche) chosen, again, there is a “wolf in a sheep’s clothes” - a =nil; `DROP DATABASE * node with Avalanche’s replication protocol adapter. From any other Avalanche node’s perspective, this node behaves like an ordinary Avalanche node (a fully featured one) - it looks like one, swims like one, quacks like one, but it is not exactly one.
And! Again, because it provides Avalanche’s data in the way suitable for the =nil; `DROP DATABASE *-based cluster to be able to track it, it is possible to generate a state and query proofs from its state or a cluster commit log, so that means one can deploy multiple absolutely independnt Avalanche database clusters, which will know nothing about each other. But! Through the I/O cluster of ours, it is possbile for them to generate state/query proofs of each other and access each other’s data through the I/O cluster as well in a trustless manner.
That means =nil; `DROP DATABASE * cluster is capable of generating state/query proofs of a client L1’s application-specific deployment and submit them to the main cluster to be verified. That literally means compressing various amount of data through so-called “validity proofs” to the main Avalanche cluster, increasing the throughput linearly (aka horisontal scaling), depending on the amount of application-specific indepedent Avalanche deployments. This approach is possible to be applied to any monolithic L1 protocol (Solana, Ethereum, any other one).
And voila! Trustless pluggable scaling requiring absolutely no changes from client protocols.
Time to wrap up.
The moral of the story is that all the applications described use the same and the only one mechanism: protocol state query proofs (query engine proofs) and protocol commit log’s state proofs. Which is only possible to be built because of the DBMS-based approach using very typical, very usual DBMS features such as:
-
Replication protocol adapters. It is only possible to access third-party databases’ data without any need to copy it inside I/O cluster because of that.
-
Query planner/engine. It is only possible to prove query over the state of a various database because of that. And it is possible to be applied to Eth, Solana or whatever through I/O cluster.
-
State partitioning. No need in handliing terabytes of state data within the same machine. This is possible to be applied to Eth, Solana or whatever through the I/O cluster as well.
- Independent Deployments. Can’t handle the load? Just get one more
database cluster up and running and you’re good to go. No need for “sharding”
or whatever.
Yes, I’m perfectly aware why sharding exists - there is a need to maintain a consistency of the only one database index which matters in every protocol’s database in this industry - account-value index. We will come to how to remove such a need in future blog posts (yes, there is such a way). Stay tuned!
It is ridiculous, by the way, the way all the database purpose gets reduced to the only only one thing - maintaining the only one key-value index. All the other data can and will be removed https://vitalik.ca/general/2021/12/06/endgame.html and everyone is okay with it.
I was even asked something like “What do you want to store in the database (it was Ethereum we were talking about) besides account-value data? It iS nOt a DaTaBaSe, what do you want?”
I never spoke to that fellow again since then. Don’t let your children be like that fellow.
And, guess what? This is possible to be applied to Eth, Solana or whatever through I/O cluster as well.
- Proper Data Management Internals. Some boring old men (who at first got their degrees instead of blogging about Bitcoins) say that OLAP-specific and OLTP-specific database load types require different storage internals than simply using RocksDB for everything.